!important 本文以讲述原理为主,不发布可直接执行的代码
由于经常出现我今天看了第二天视频就没了的情况,所以特别喜欢的视频我都会down下来保存到本地,当然三连给up是肯定的,网上已经有不少可以直接下载的插件了(特别是chrome插件,但是批量下载还是得手动来。
所以我们先来了解一下怎么手动下载B站视频
此处以我的一个视频为例(gank钓鱼网站)原料如下
- Google Chrome/Firefox(PC端)
- aria2c (是的,下载怎么能少了它呢
- curl
- 代码执行环境(如cmd/powershell/bash
首先打开页面,按F12打开调试窗口,刷新(因为我需要用到sources中的内容,不刷新通常拦截不到)此时打开“网络”选项卡,你会看见密密麻麻的一堆网络请求地址,像下面这样
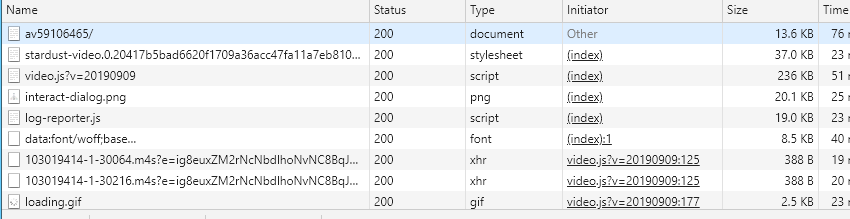
先排除掉资源文件,比如字体,css,js,因为视频音频数据基本不可能存在这些文件中,所以可疑的数据就只剩下两条了:那两个m4s的xhr请求(就是我们平常说的ajax请求)
接下来要做什么已经显而易见了,打开“源”选项卡,找到这个页面
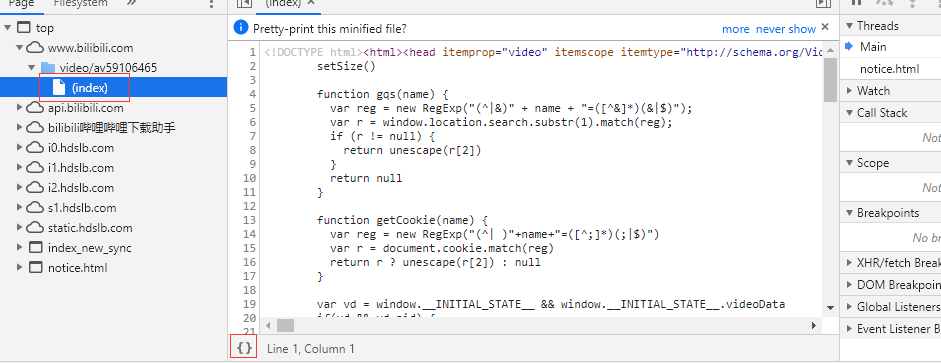
看见这个index了吗?点它,这就是当前页面的源文件(并非你看到的这个页面,因为你看到的这个页面是经过js和css处理过的),顺便按一下左下角的大括号,美化代码,ctrl+f搜索刚才看见的那两个m4s,可以发现他们在一个__playinfo__的json里

第一次找到的时候我其实是很震惊的,B站这个播放器的音频和视频是分开的,这两条url也就是我们要找的下载地址了
你以为这就结束了?没有!

直接使用aria2c 下载会报错,用curl查看提示403forbidden,既然B站下载可以,那我们让请求参数更像B站的下载请求就行了啊,这里直接说结果:加上–refer参数,refer是指你在哪个页面请求的这个地址,对应的是网络请求的header中的refer,所以完整的命令是
aria2c –refer=’base_url’ ‘video/audio url’
至此,手动下载的部分说完了,下面的内容就简单很多了
批量下载适用于解放手工劳动的,如果批量也这么下那可太麻烦了,批量下载一般会在程序中直接下载,甚至连视频音频的合并都做了,但是我懒(
于是我采用的是类似于爬虫的思路,只爬取url,使用url生成下载命令并保存为文件,当前的批量下载针对多个分p的,分p的获取在查看源那一步搜索分P标题就可以找到一个名为 __INITIAL_STATE__ 的json,分p在pages数组里,其它参数这里暂时用不到
b站视频播放的url有一个p参数,就是分p序号,所以我们令max=len(pages),来循环获取每一p的url(p=i+1),把生成的command写到文件中就万事大吉了
为了方便区分文件内容,来认识一下aria2c的-o参数,指的是下载文件名,在生成下载命令的时候带上这个参数能够让文件更便于区分。
那么这篇文章到此结束,欢迎来B站找我@EnderCaster